Architettura dei dati
Nella presente documentazione viene descritta l'architettura dei dati che sta alla base dei flussi di lavoro del nostro team.
In questo primo capitolo, in particolare, vengono illustrati l'approccio e la struttura generale dei sistemi utilizzati per la gestione e l'elaborazione dei dati, che sono schematizzati nell'immagine riportata di seguito:
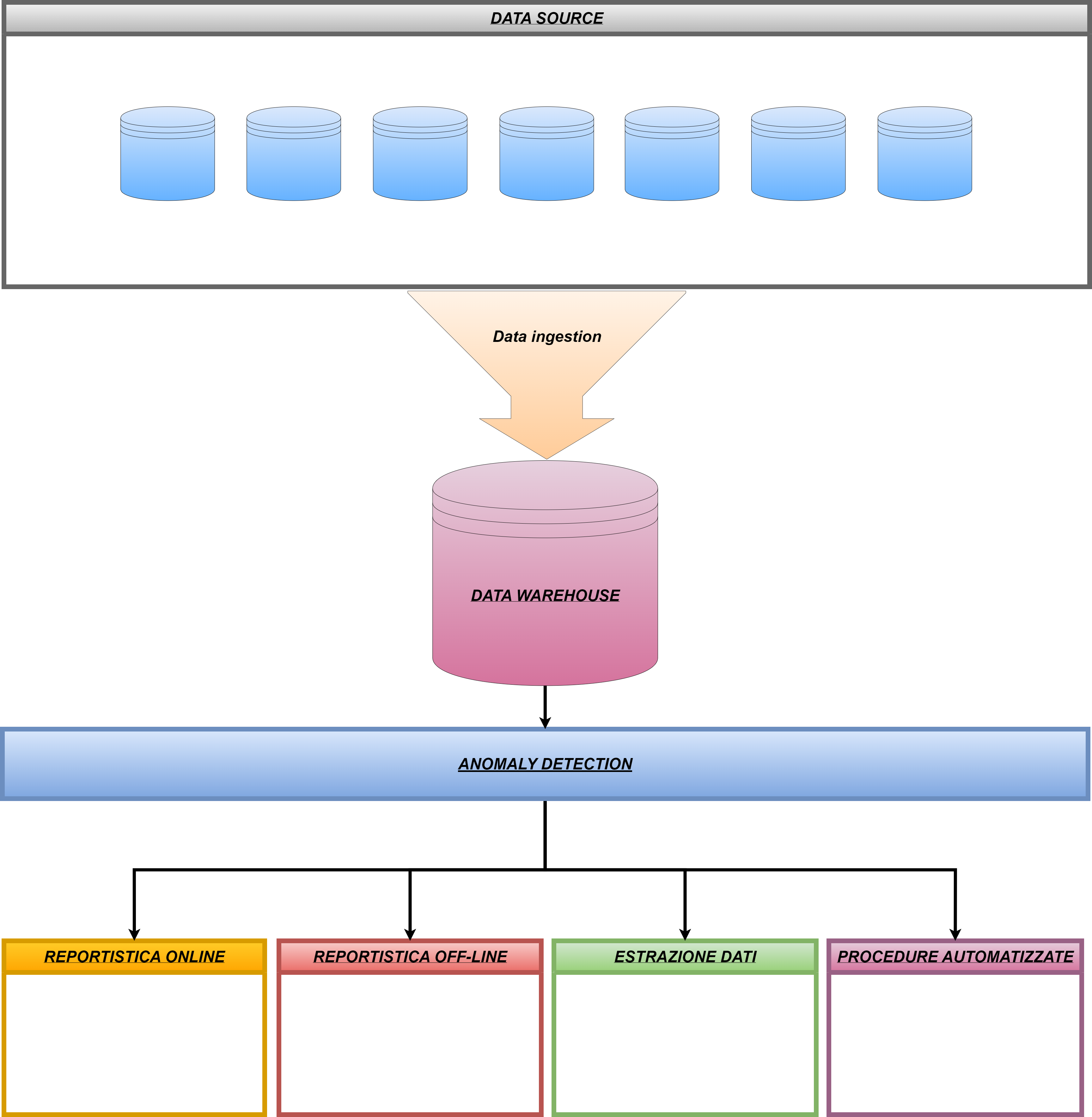
I dati grezzi provenienti dalle diverse data source vengono caricati all'interno del data warehouse (DWH) attraverso un processo customizzato di data ingestion.
I dati così archiviati all'interno del DWH sono in questo modo disponibili per essere elaborati in base alle necessità di analisi.
In sostanza l'approccio che viene utilizzato è quello di un processo ELT (Extract, Load, Transform) in cui il dato grezzo viene estratto dal data source, caricato all'interno del DWH e poi, in una fase successiva trasformato.
A valle delle elaborazioni dei dati effettuate all'interno del DWH la correttezza dei dati viene controllata tramite un sistema di Anomaly detection che ha la funzione di individuare e notificare al destinatario di riferimento eventuali anomalie riscontrate nei dataset risultanti dal processo di trasformazione. In questo modo l'anomalia può essere corretta direttamente nel data source, evitando errori e/o disallineamenti nella reportistica o nelle estrazioni dei dati per utilizzi successivi.
Una volta trasformati all'interno del DWH ed eventualmente corretti grazie al sistema di anomaly detection, i dati sono pronti per essere utilizzati per i seguenti scopi:
- visualizzazione nella reportistica on-line;
- visualizzazione nella reportistica off-line;
- estrazione per utilizzi successivi;
- utilizzo per procedure automatizzate.