DB di analisi
Vediamo di seguito come è strutturato l'unico DB di analisi che è attualmente presente all'interno del nostro DWH, il database BI.
Gli schemas presenti all'interno del DB BI, come mostrato nell'immagine seguente, possono essere suddivisi idealmente in tre categorie:
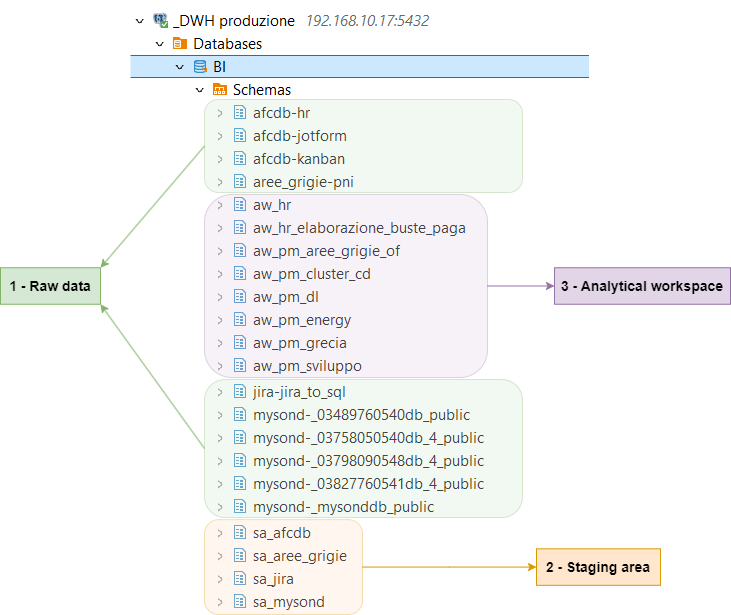
1 - Raw data
contenuto:
questi schemas ospitano, all'interno della cartella "Foreign Tables", un collegamento alle tabelle (e alle viste se presenti) dei database di tipo raw data store (che contengono il dato grezzo, appunto). Questo collegamento viene ottenuto tramite foreign data wrapper (FDW).
Questo ci consente di avere all'interno del nostro DB di analisi i dati grezzi provenienti dalle più disparate data sources, in modo tale da agevolare le operazioni di join tra dati derivanti da sorgenti diverse, ma senza dover fare una copia locale dei dati.
nomenclatura:
la nomenclatura corretta da utilizzare per questi schemas è nomeDB-nomeschema dove nomeDB è il nome del raw data store di riferimento e nomeschema è il nome dello schema che sto considerando all'interno del raw data store di riferimento. Ad esempio, le Foreign Tables relative allo schema "kanban" del database "afcdb" andranno nello schema denominato "afcdb-kanban" del database di analisi BI, e così via per gli altri schemas.
2 - Staging area
contenuto:
negli schemas della staging area possono essere create tabelle, viste o viste materializzate necessarie a pulire, storicizzare o aggregare/strutturare il dato per elaborazioni successive.
Si tratta di una prima elaborazione del dato che non è indirizzata ad uno specifico utilizzo (ad es. ad uno specifico report), ma bensì è funzionale ad ogni possibile trasformazione/analisi che dovrà essere svolta nelle fasi successive.
Ogni schema della staging area fa riferimento ad uno specifico raw data store. Le elaborazioni effettuate nella staging area dunque, utilizzeranno sempre come dati di partenza i raw data ottenuti tramite FDW dal relativo raw data store.
nomenclatura:
la nomenclatura corretta da utilizzare per questi schemas è sa_nomeDB dove "sa" sta per staging area e nomeDB è il nome del raw data store di riferimento.
3 - Analytical workspace
contenuto:
l'analytical workspace è lo spazio di lavoro dedicato alla trasformazione e all'analisi dei dati. In questi schemas possono essere create tabelle, viste o viste materializzate specifiche per l'utilizzo finale che ne vogliamo fare (ad es. per uno specifico report).
Ogni schema dell'analytical workspace è rivolto ad uno specifico ambito o destinatario finale. Le trasformazioni e le analisi effettuate nell'analytical workspace possono utilizzare dati provenienti da qualsiasi data source, attingendo sia dai raw data che dai dati elaborati nelle staging area.
nomenclatura:
la nomenclatura corretta da utilizzare per questi schemas è aw_nomedestinatariofinale dove "aw" sta per analytical workspace e nomedestinatariofinale è il nome dell'ambito o del destinatario finale al quale sono rivolte le analisi effettuate (ad es. se lo schema che sto creando dovrà contenere delle viste per alimentare un report on-line, il nomedestinatariofinale corrisponderà al nome dell'area di lavoro del servizio BI in cui pubblicherò il report).
No Comments